参考先行者的制作过程,生成母音貌似有两种思路:
- 以正弦波为起点,将不同振幅的正弦波叠加起来模拟泛音列。
- 以噪声为起点,用滤波器把噪声塑造成接近人声的频谱形状。
我觉得两者的主要区别在于非倍频成分的处理。
对噪声滤波时一般不会把非倍频成分抑制到接近无,
而这些成分可能会使生产的音色更接近人,也可能会影响音色的统一性(待考证)。
要说共同点的话,那就是两者都需要真实人声频谱作为参考。
我的做法是:
- 一、分析自己的母音频谱,提取泛音列的幅值系数
- 二、根据系数,生成正弦波,叠加生成母音的「模板」
- 三、在模板的基础上用滤波器进行音色的细致调整
第一、第二步在 Matlab 中进行,第三步在宿主软件中进行。
如图所示,这是一个音高为 C4 的母音あ的部分频谱,横轴网格为泛音列:
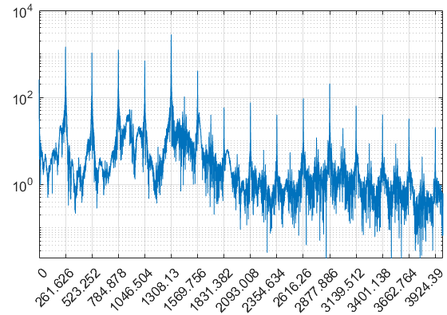
可以看到在倍频的位置是有明显的针状突起的。
纵轴的单位不重要,绝对数值大小也不重要。
获取系数之后就可以进入生成的步骤了。
我写了简单程序用于生产母音模板片段,有优化空间,仅供参考:
Fs = 44100; % 采样率 (Hz)
n = 1:Fs; % 生成采样点个数,此处为时长1s,可以改
F0 = 261.625565; % C4的基频 (Hz),可以改
series = 64; % 最高谐波次数,可以改
Fn = 1:series;
Fn = 2*pi*F0*Fn; % 谐波频率 (rad/s)
weight = [……]; % 控制音色的谐波振幅系数,需要事先获取
% 叠正弦波
voice = zeros(size(n));
for i = 1:series
voice = voice + weight(i).*sin(Fn(i)./Fs.*n);
end
audiowrite('文件名.wav', voice, Fs); % 保存到 wav 文件
% sound(voice,Fs); % 试听 % 这行是注释
我想设计一个比较中性的音色,
参考日语元音图,简单选取了经典男女共振峰 F1、F2 各自的中点为设计值:
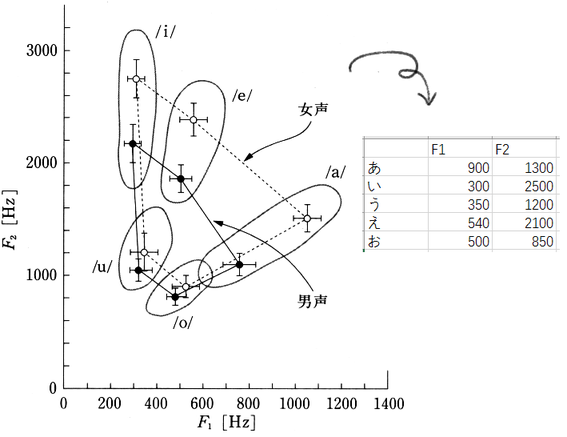
以及,F3不改动,保持模板的3200Hz左右。
F4是一个比较体现音色特征的参数,不随发生状态改变,目标调整到4200Hz左右。
接下来的工作转移到宿主中进行。
- 调整输出片段的包络,画出接近真人发声的音头、音尾淡入淡出。
- 参考设计的共振峰数值,用滤波器调整频率成分
- 加混响与轻微噪声模拟语尾息
到这一步基本算是完成了。
检查时频图时注意到,合成母音在全频段都有比较明显的谐波,
这不太符合人声的特征。
对比资料,如图,可以看到あ以外的母音都有比较明显的空白频段:
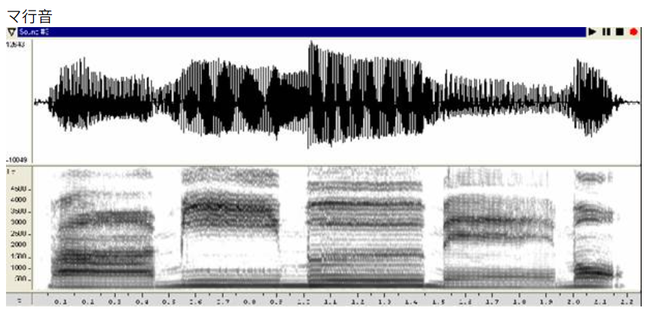
い在 1000Hz~2600Hz 是近乎空缺的,え的 1000Hz~200Hz 也是类似的表现;
う的 2000Hz~3000Hz 成分较弱,お的1500Hz~3000Hz表现类似。
还观察到所有元音在4000Hz~6000Hz中的某处处会出现空白,
此处似乎属于梨状窝的反共振峰?
这个反共振峰男女都有,似乎男性表现得更显著。
参考上述数据,再次使用滤波器削减部分频段。
最终得到了这样一个文件:_あ_い_う_え_お.wav
国内多半打不开,所以我传了一份网盘,草(……
评价:
- 听感较闷,有高频缺失感
实际上从设计开始就可以预料到高频缺失的情况
正弦波序列只包含到64次谐波,频率上限大约为261×64=16704 (Hz),
相比人类听觉上限20000Hz,确实缺了一大段。
但从活人素材里提取的谱在5kHz以上已经很弱了,
和噪声的起伏差距不大,有自然好,但对音色塑造不起关键作用,
总之谐波次数取到几还是看个人感觉吧……!
コメントをお書きください