大部分不依靠声学模型的变声器中的声质参数,
以及歌声合成软件中的性别参数(ジェンダーファクター),
实质上是针对共振峰位置与分布进行调整的滤波器。
以 UTAU 的 g(默认值为 0)为例:
如果将 g 设置为负值,合成器就抑制原有的共振峰,激励更高频的部分,
达成共振峰向高频移动的效果,使音色更接近童声。
与此同时,这种不够精准的滤波改变了 F1、F2 的频率比,导致元音音位的偏移:
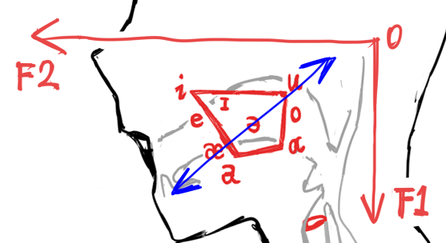
蓝线仅示意,不代表真实的偏移趋势
处理后的人声在听感上更扁,发音靠前。
挤出来的萌声アニメ声ロリ声
反之同理,将 g 设置为正值,人声在听感上更圆,发音靠后。
借助 g 值的调整可以稍微模拟一些歌手发音位置的变化:
- g 设负值:偏前的发音听起来更流行、更俏皮清亮
- g 设正值:偏后的发音听起来更古典,更厚,接近合唱(chorus)唱法
虽然是这样,但 g 调整性别感的效果肯定比发声位置更明显,一般情况不宜动用。
我之前有的 cover 就在实验 g 参数,这里挑了两处听感相对比较明显的出来:

公然の秘密 - 「 逃れらんないの一旦嗅いだら最後よ 」

シンセリティパルス - 「 この目、肌、声と 心のままで 」
コメントをお書きください